[Python] json.dumps的参数:ensure_ascii
起源
这部分无关Python,只是让我想起了Python的json.dumps()而已。
今天,我在看JSON Lines介绍的时候看到了这么一句话:

JSON allows encoding Unicode strings with only ASCII escape sequences, however those escapes will be hard to read when viewed in a text editor.
当我读到这句话的时候,我能看懂”ASCII escape sequences“是”ASCII转译序列“的意思,但我不明白的是:JSON不是要求用UTF-8的么,为什么还要转译呢?
当时的我,还不知道JSON中表示非ASCII字符的两种方式。(不太确定这个说法对不对)
两种不同的表示方式
如果你用过几次json.dumps(),你一定知道这个函数有一个ensure_ascii参数,而当它改变时,输出的结果也就有不同:
json 中的ensure_ascii=False (貌似用的是python 2,但不重要)
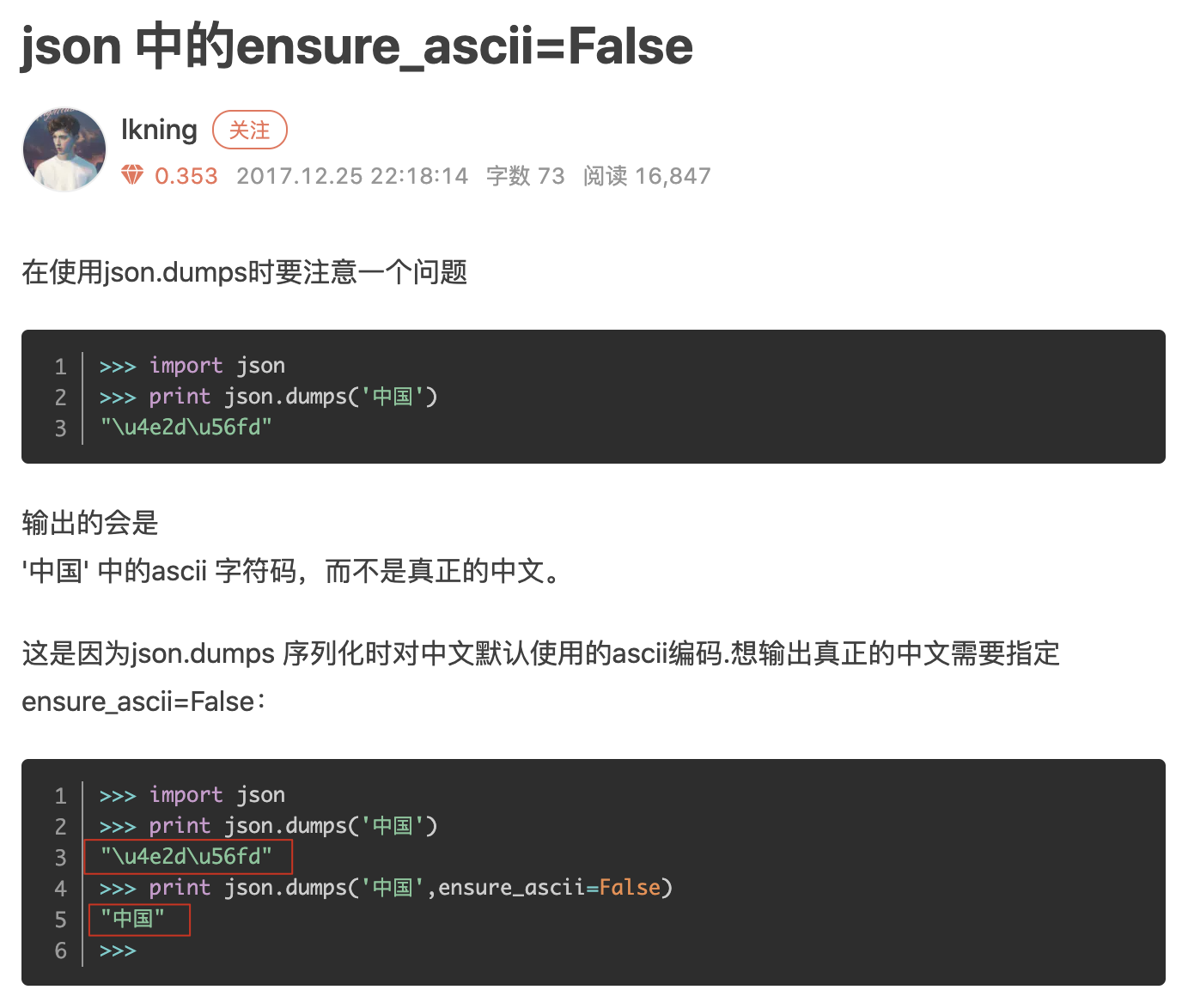
可以看到,ensure_ascii影响了序列化后的最终形态。
尽管样子不同,但是你会发现,使用json.loads()读取时却并不需要特殊处理,效果是一样的。
读取实验
与上面的对应,右边的\u4e2d\u56fd就是中国两个字在Unicode中的表示。
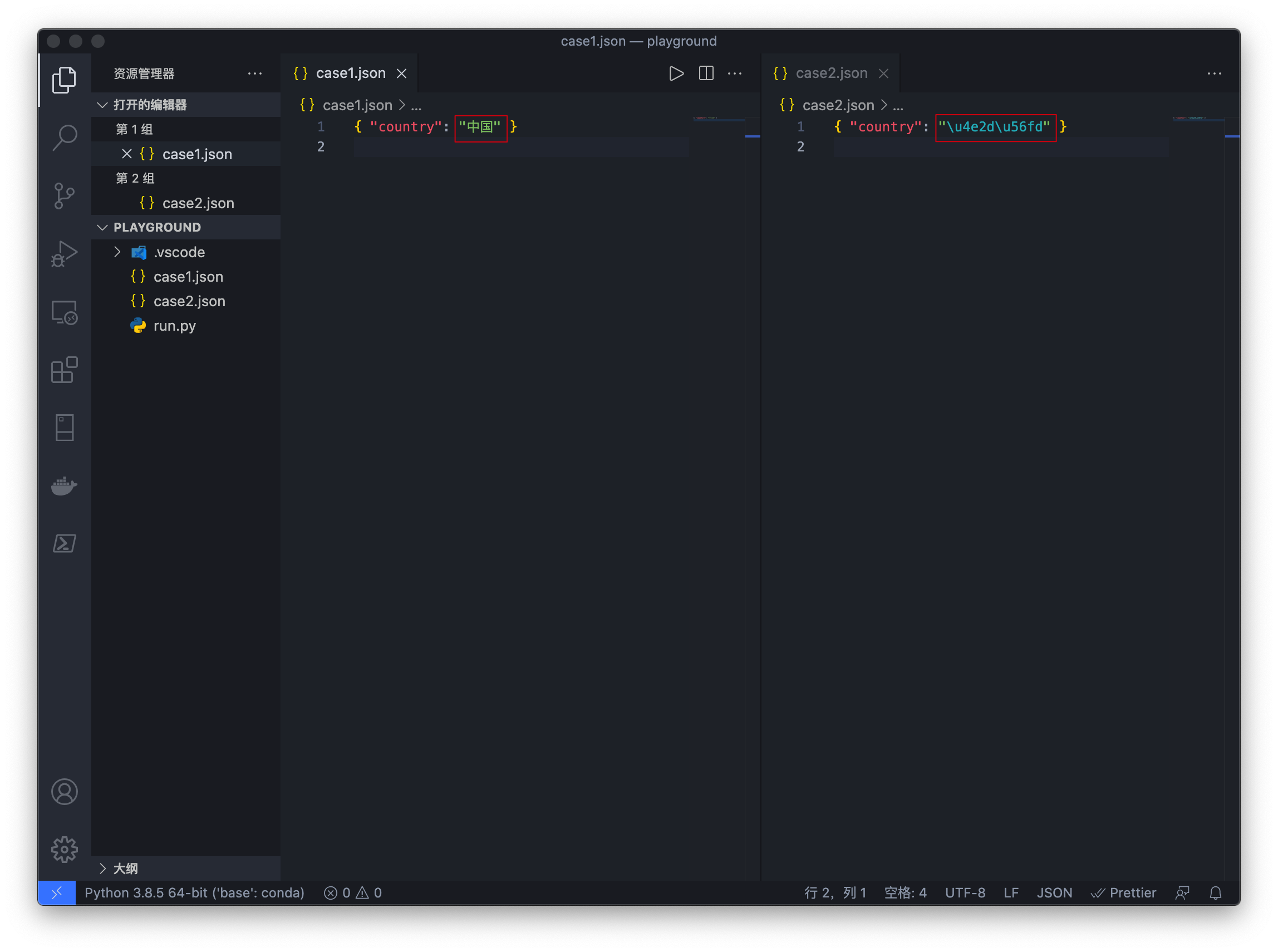
用Python测试下:
1 | # coding=UTF-8 |
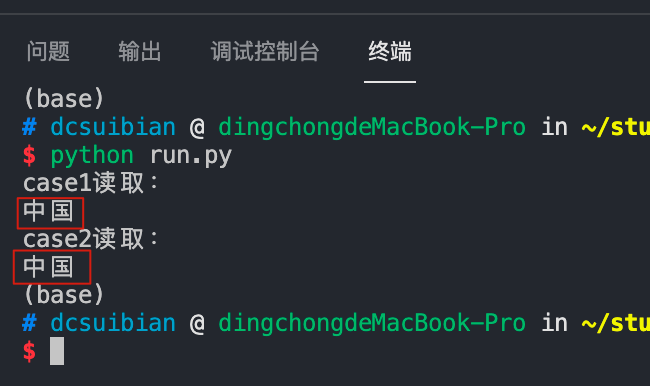
可以看到,输出的时候都输出了”中国“两个字,可见写中国和\u4e2d\u56fd的效果是一样的,并且读取的时候不需要增加任何参数,自动完成。
实际上,这并没有什么奇怪的。不少语言的源代码文件都支持在字符串里以\u4e2d\u56fd或中国同样的方式表示非ASCII字符。
只要让此文本的处理器把字符串里的单个反斜杠\视为转译字符就可以。
真正重要的是为什么?
为什么?
(以下只是我的一些猜测)
如前所述,JSON是要求使用UTF-8的,所以我不明白为什么要使用ASCII转码的方式来表示同样的内容。
但这个问题其实并不在于JSON,而是在于文本文件本身,还是字符编码的问题。
举个例子,如果我现在拿到了一个.json文件,但是我使用一个非常老的编辑器,或者我使用的编辑器使用不同的编码打开它会怎样?
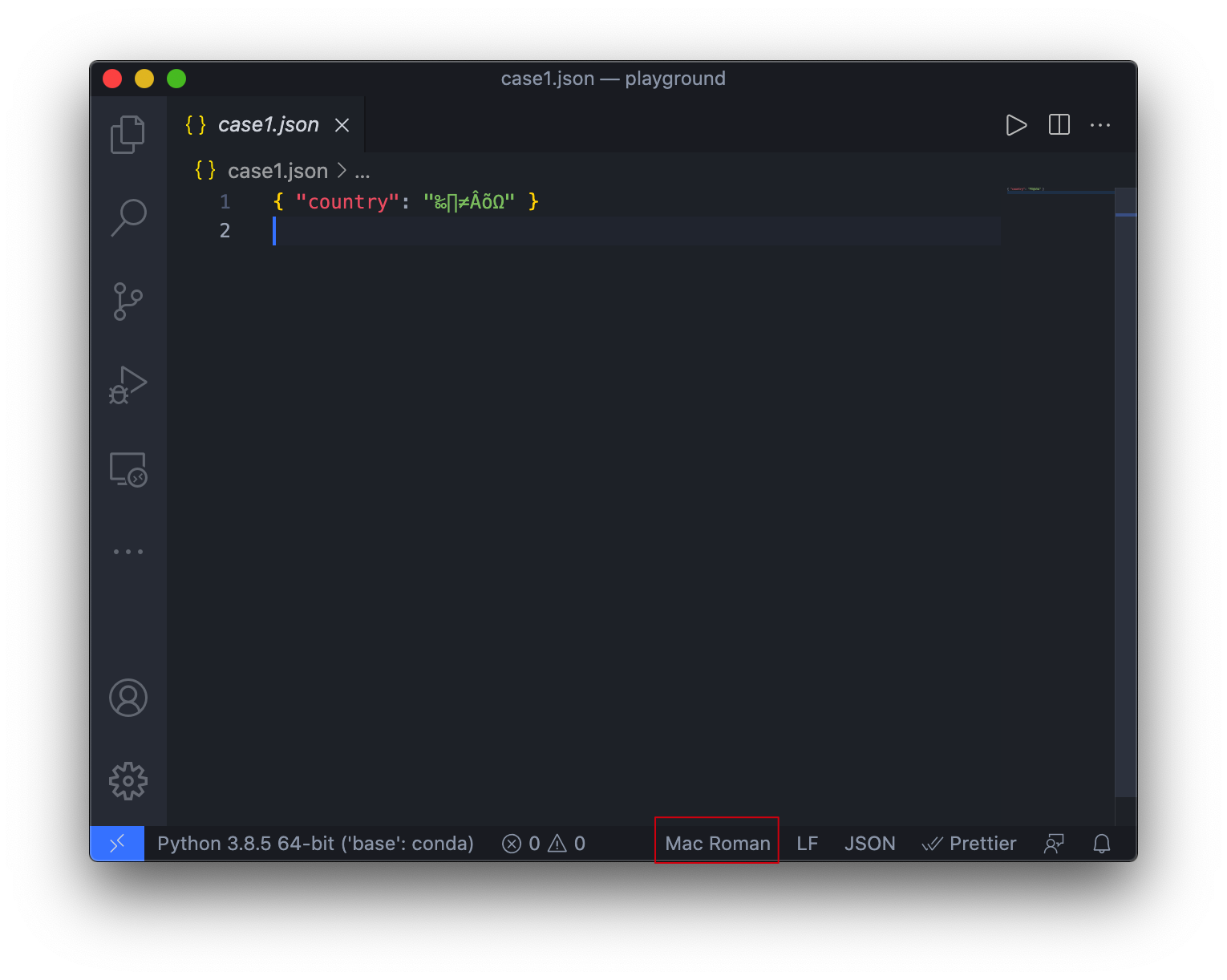
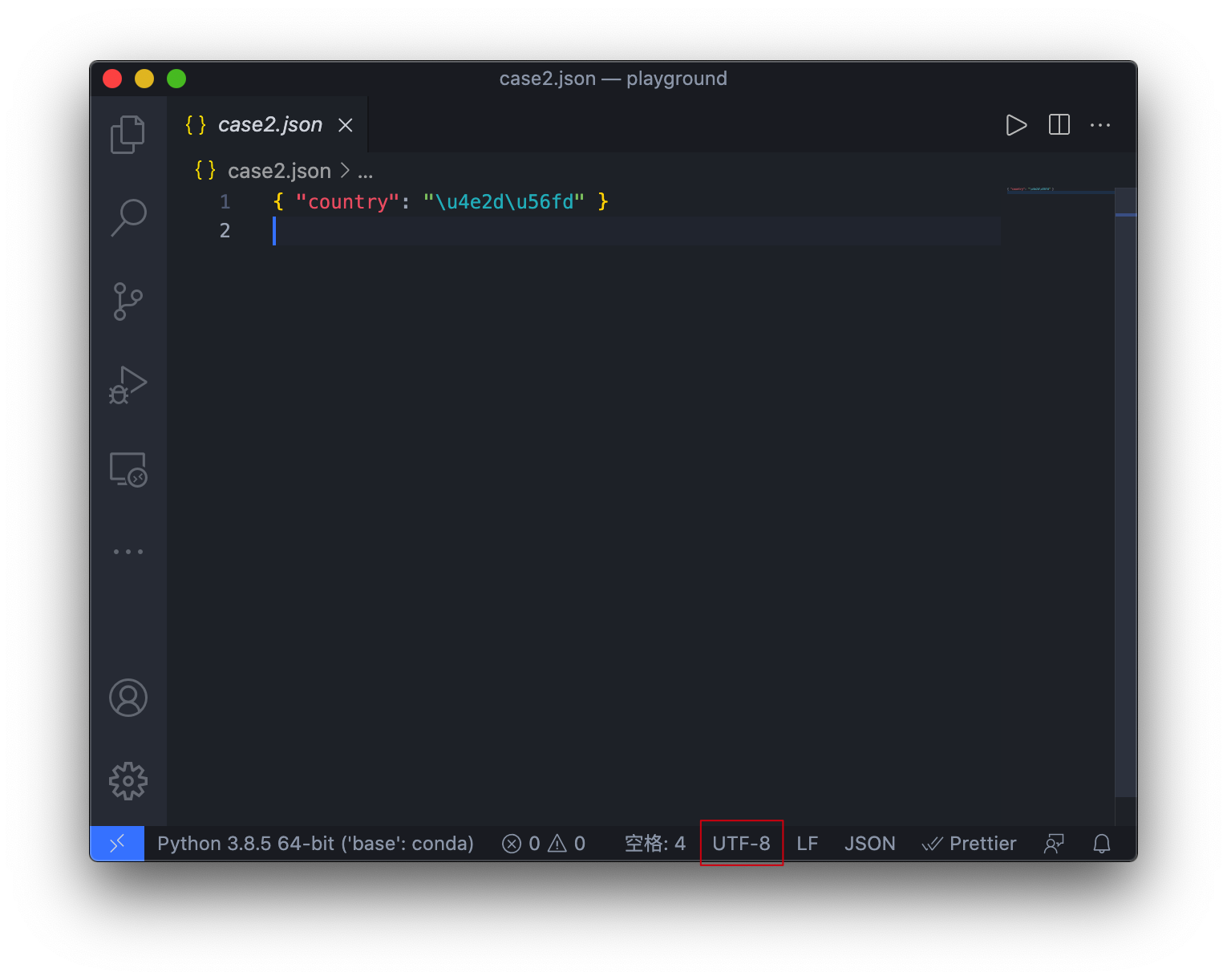
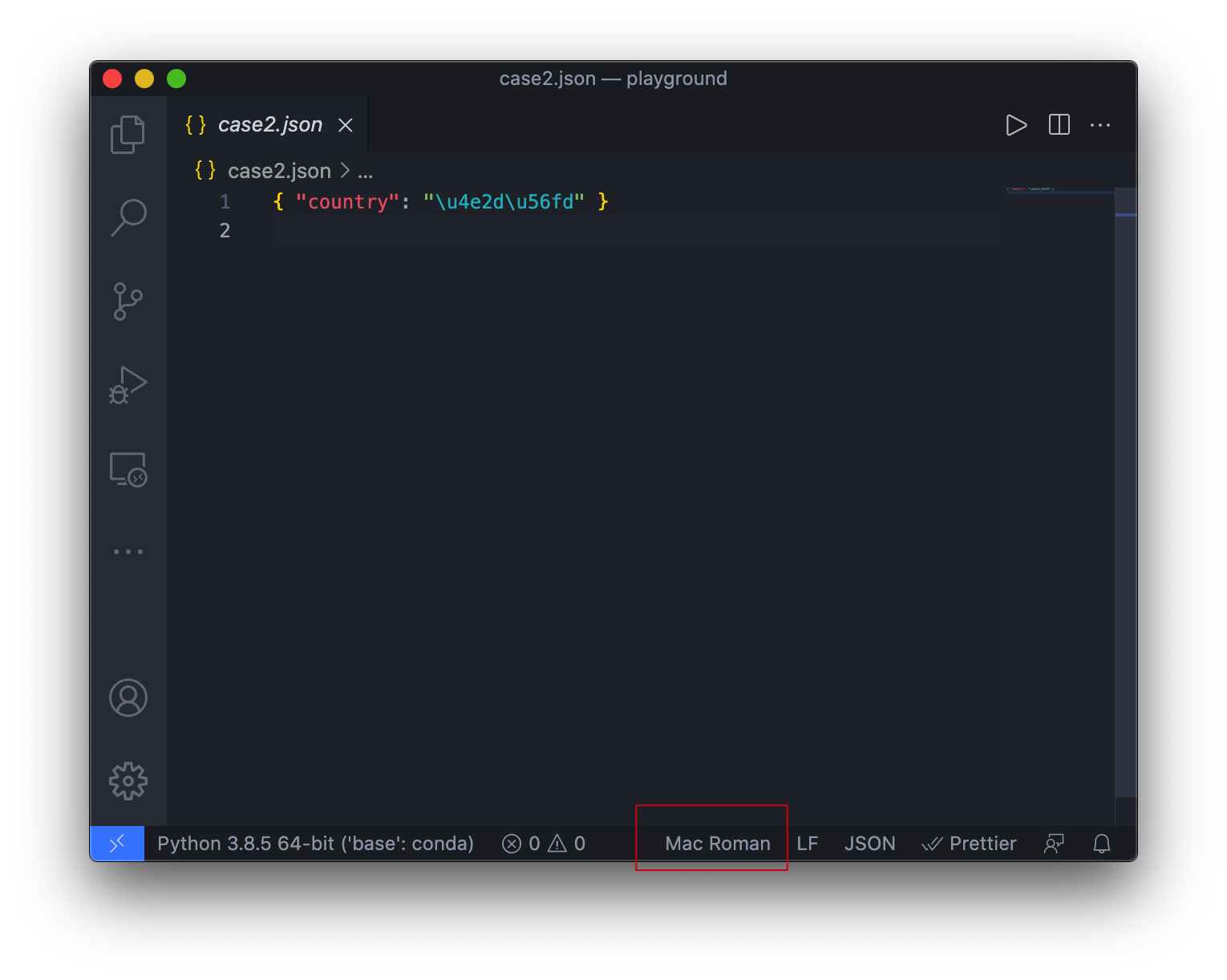
可以看到,当使用了错误的字符编码打开文件时,使用中国这种方式编写的文件出现了乱码问题,而使用\u4e2d\u56fd这种方式编写的文件则完全没有问题。
实际上这跟字符编码的历史有关。我相信是个程序员都知道ASCII码,相当于字符编码的”老祖宗“了。因此,大部分编码都是跟ASCII兼容的。你可以试试看,当你只用ASCII字符集里的字编写文本,当你切换编码时,你会发现丝毫没有影响:
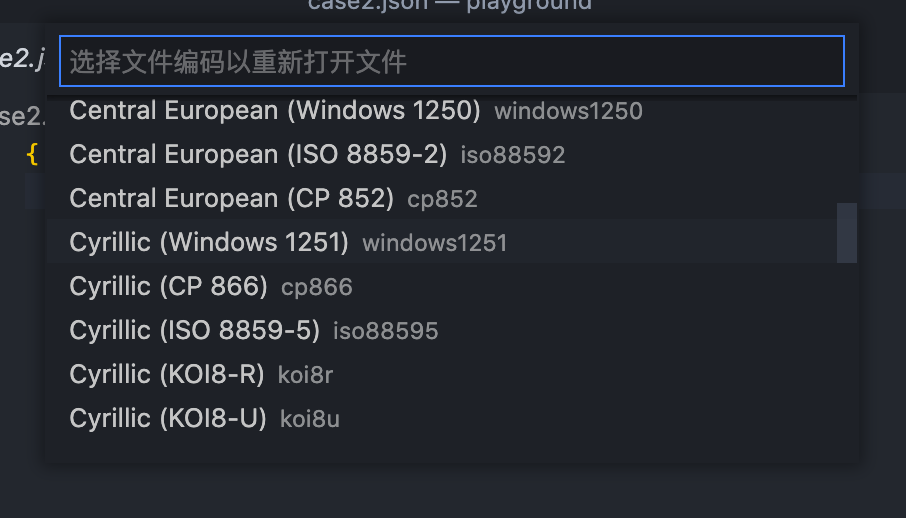
但是,那些非ASCII的字符就没那么好运了,尽管现在大家都在提倡用UTF-8,但免不了还是有用其它字符集的文件。
因此,如果你使用一开始使用的是转译的方式,那么打开文件时就不会出现乱码,而用户本身看到\u4e2d\u56fd大概也能猜到这是需要转译的。
这只是个例子。现实中可能有更复杂的情况,比如当数据流经一个管道时,管道只能处理ASCII符,否则就会报错,这种情况下转译也比较适用。
选哪种?
既然你已经知道了区别,那么就是选哪种的问题了。
使用转译的方式(
ensure_ascii=True)兼容性更好,不容易出现乱码,但问题就是”however those escapes will be hard to read when viewed in a text editor“说的那样,当使用文本编辑器打开时,不容易看懂。使用非转译的方式(
ensure_ascii=False)更直观,当你想要打开它看看内容时,就比较易于理解。
实际上,如果你要接触只能处理ASCII字符的系统,那就没得选,只能采取转译方式。
而我个人更偏向非转译的方式,因为目前我用到的软件系统对UTF-8的支持都还是挺不错的,如果有软件不支持,那我更倾向于换一个软件。
思考
如果你用过IDEA,你会知道文件编码中有一个设置:
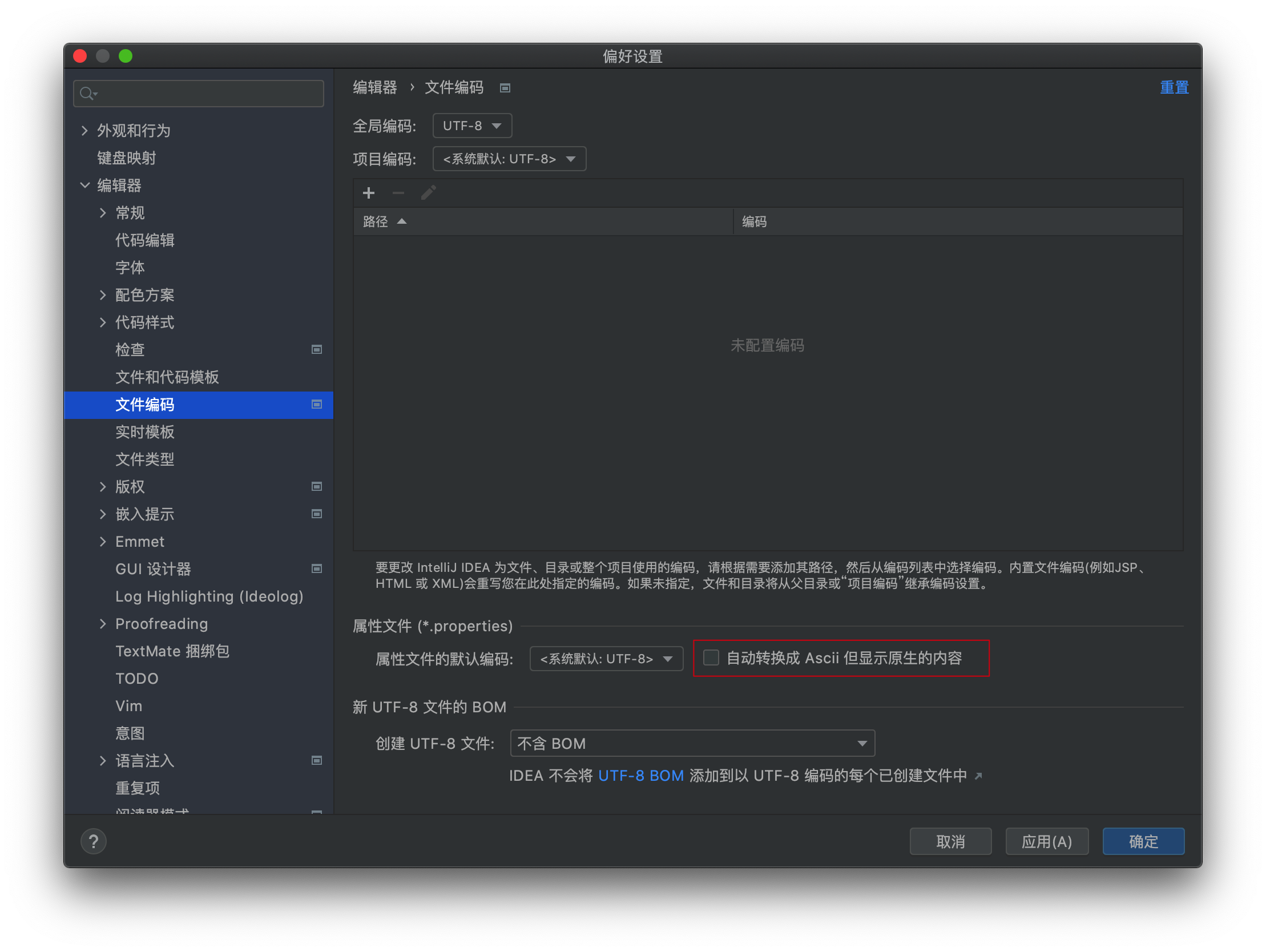
如果有兴趣的话,可以自己建一个.properties文件,在开和关的情况下写一些非ASCII字符,用文本编辑器打开看看。
建议:这个选项跟你的同事的保持一致,如果你没有同事,那建议不启用。